In this post, we discuss text classification tasks and GLUE benchmark dataset.
GLUE Benchmark

In NLP, it is quite challenging to properly evaluate a NLP model. So they built a standard dataset that is used for the general evaluation of NLP models. One of them is GLUE benchmark, General Language Understanding Evaluation, which is a collection of resources for training, evaluating, and analyzing natural understanding systems. This consists of 9 different existing datasets in NLP, such as sentiment classification task dataset.
Even though one model shows very good performance, it may fails in other task. So it measure the generalization power of NLP models, and provide a diagnostic analysis.
Task Outline

The 9 datasets are either single sequence task or sequence pair task. All the tasks are important. Let’s take a look
Acceptability Judgement: CoLA


This task aims to identify the grammatical acceptability of a sentence, with the goal of testing linguistic competence of NLP models. CoLA is a short name for the Corpus of Linguistic Acceptability, where this acceptability judgement task requires identifying challenging grammatical contrasts. But not all linguistic examples are suitable for acceptability classification. The linguistic evaluation, they mean, are judging syntactical, morphological, or even lexical/semantical acceptability or errors in the text. Their scope excludes some parts in the figure above.

We show the data statistics of CoLA. We can see that the top-3 large datasets in Kim and Sells, Devin, and Ross in the in-domain dataset. The out-of-domain dataset is prepared to test generalization ability of NLP models, where they don’t have the training set, but only provide development/test sets. In such setting, a model has to overcome low-resource (or zero-shot) dataset.

We show few samples in CoLA. Each sentence is labeled based on the acceptability.
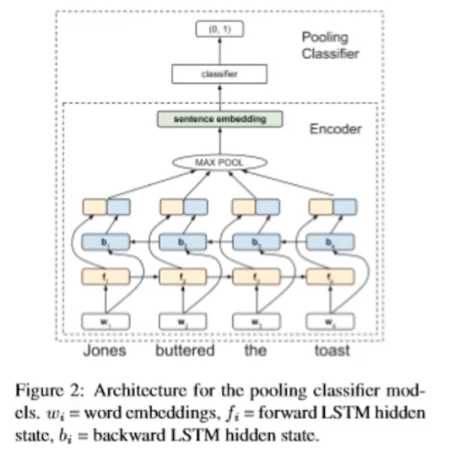
Using the Bi-directional LSTMs for CoLA, each word is embedded not only the left-to-right direction, but also keep the right-to-left processing. Formally, these forward/backward embeddings are concatenated for each word, and it uses them as the input of the final classifier.
Sentiment Classification: SST-2
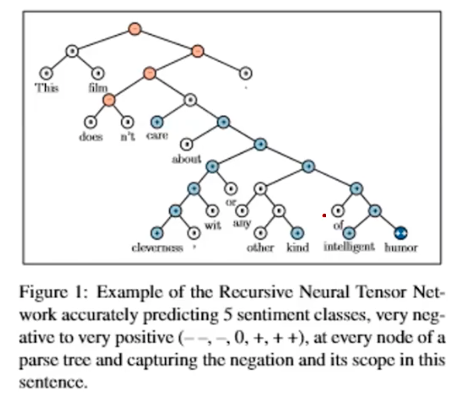
Let’s assume we’re trying to find out the sentiment of a speaker, when he or she says “This film doesn’t care about cleverness, wit or any other kind of intelligent humor.” To solve this, one can break down the sentence into each word and analyze the sentence structure by aggregating each word’s sentiment. This is called a parse tree of a sentence. By assigning some sort of scores on each word in the vocabulary, we can evaluate a parse tree of a sentence whether it delivers a positive or negative opinion. Reserachers used to propose rule-based heuristics to build the sentence structures. But, nowadays no more! We let the deep learning algorithms do it for us.
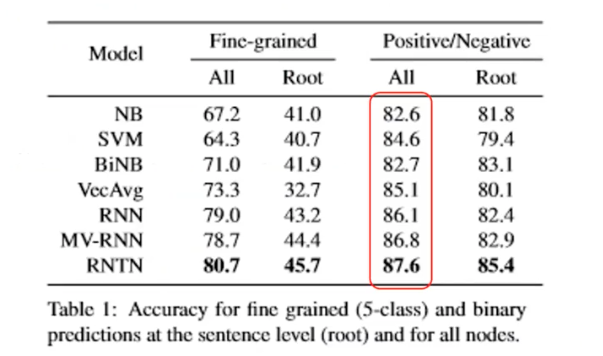
In SST-2, we use the two-way (positivie/negative) class split, and use only sentence-level labels.
Sentiment Classificaiton: IMDB


IMDB Large Movie Reviews Corpus is a binary sentiment classification dataset, not one of GLUE dataset, containing 50,000 polarized (postivie or negative) movie reviews, split into half for training and testing. It has comparably longer text than that of SST-2, such as a document level or paragraph level text. Usually, we use several sentiment classificaiton datasets to train such sentiment analysis models.
Paraphrase Identification: MRPC
Paraphrase identification identifies whether two sentences are of same semantics. Here the input is a pair of setences. Microsoft Research Paraphrase Corpus (MRPC) consists of 5801 pairs of sentences, each accompanied by a binary judgement indicating whether human raters considered the pair of sentences to be similar enought in mean to be considered close paraphrases. They have 68% of samples labeled as positive ones (little unbalanced). As this dataset was introduced in 2005, they have relatively small amount of samples. But, it is helpful to test sparse data scenarios, where, in practice, it is common to have small amount of data available.
Paraphrase Identification: QQP
Quora Question Paraphrases (QQP) consists of over 400,00 lines of potential question duplicate pairs. Each line contains IDs for each question in the pair, the full text for each question, and a bianry value that indicates whether the line truly contains a duplicate pair.

That is, in QQP, the task is to predict whether a pair of question sentences are of same meaning. This dataset is regarded more chellenging as they have bigger data samples, which requires bigger generalization power. The ground-truth labels are actually little noisy in this dataset, so be aware.
Similarity Prediction: STS-B

Sementic Textual Similarity Benchmark (STS-B) is a collection of sentence pairs drawn from news headlines, video, and image captions, and natural language inference data. STS is the assessment of pairs of sentences acccording to their degree of semantic similarity. So, this dataset is regarded as another dataset for sementic similarity analysis.
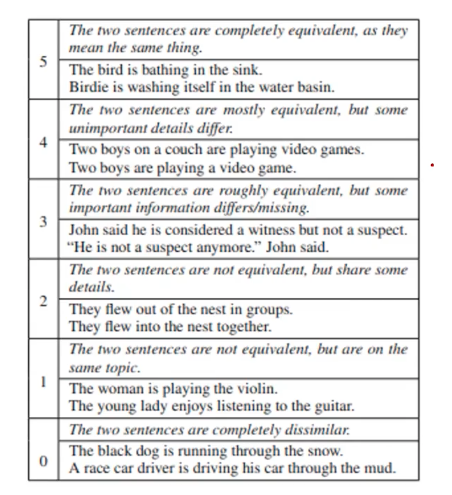
Each pair is human-annotated with a similarity score from 1 to 5; the task is to predict these scores. Following the common practice, the socres were measured using Pearson and Spearman correlation coefficients. The notion of explanation in STS-B is also noted in each sample.
This benchmark was introduced in SemEval (semantic evaluation), which is an yearly workshop with diver NLP challenges.
Natural Lanuguage Inference: SNLI

Understanding entailment and contradiction is fundamental to understanding natural language. They used to regard the ability to understand, given a pair of setnences, whether the second sentence is in the relationship of entailment or condtradiction to the first sentence. The task of natural language inference (NLI) is well positioned to serve as a benchmark task for reasearch in NLP.

Stanford NLI (SNLI) corpus is a collection of 570K human-written English sentence pairs manually labeled for balanced classification with the labels entailment, contradiction and neutral. Given a text and hypothesis sentence, the entailment judgement means that if the text is true, (e.g. “A soccer game with multple males playing.”), then the hypotheis is also true (e.g. “Some men are playing a sport.”).
It was very challenging to the NLP models at the time. Only a signle lexical changes may lead to the change in the judgement. Succeeding this datset, many NLI dataset were proposed that requires improving the reasoning power of models to capture this inference relation between sentences. In recent, neural models also must handle phenomena like lexical entailment, quantification, coreference, tense, belief, modality, and lexical and systactic ambiguity. This was the first NLI datset introduced.
Natural Lanugage Inference: MNLI

SNLI is not sufficiently demanding to serve as an effective benchmark for NLU because its limited domain (image captions). To overcome this limitation of SNLI, Multi NLI were introduced, representing both written and spoken speech in a wide range of styles, degrees of fomarlity, and topics. It has 433K pairs of setences, 393K for training and for 40K for testing and development.
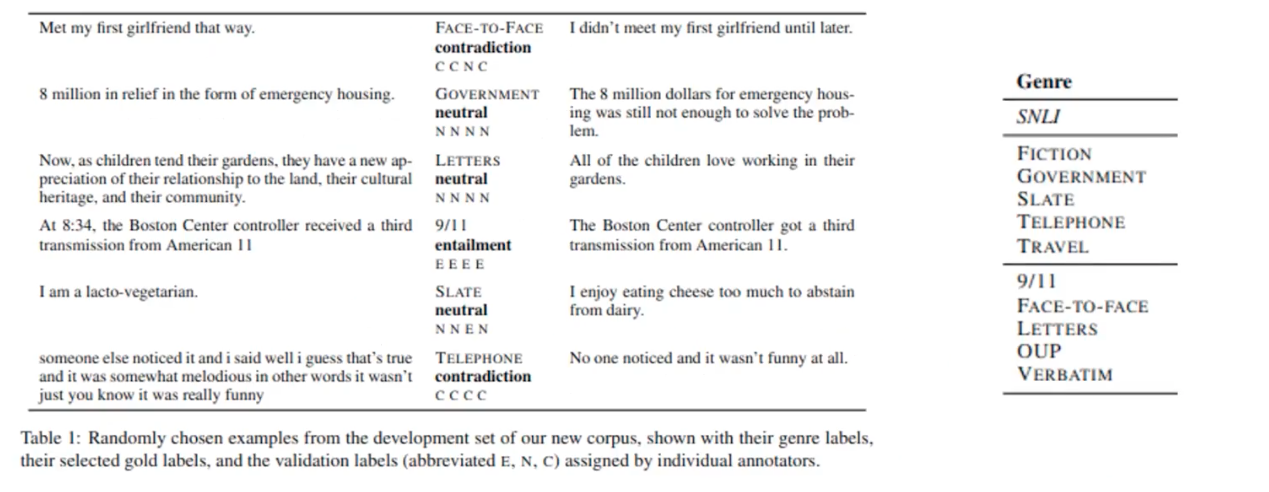
It has longer text, of both written and spoken language, sourced from additional domains (genres) such as fiction or goverment papers. The genres are quite diverse in MNLI it even used face-to-face dialogues to source the text. In general, hypothesis sentences in MNLI cannot be derived from their premise sentences. Compared to SNLI, where labelers may have similar biases during the annotation based on the image captiones, MNLI is much more diverse and challenging. For each sample pairs, they also annotated its corresponding genre.
Nautral Language Inference: XNLI

Even though we can use MNLI, resource-poor languages such as Korean used to suffer from sparse datset. To this end, people translated (both by human and machine translation) MNLI into such languages.
The Corss-lingual Natural Language Inference (XNLI) corpus is a crowd-sourced collection of 5,000 test and 2,500 development pairs for MNLI. The pairs are annotated with textual entailment and translated into 14 languages: French, Spanish, German, Greek, Bulagrian, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, Hindi, Swahili, and Urdu. Each premise can be associated with the corresponding hypothesis in such languages.
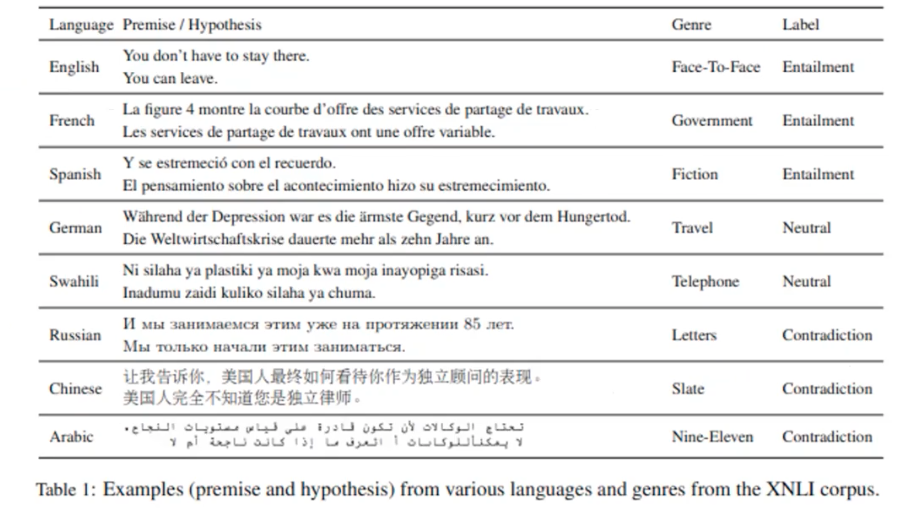
The corpus is made to evaluate how to perform inference in any language (including low-resources ones like Swahili or Urdu) when only English NLI data is available at training time.
Natural Language Inference: QNLI
SQuAD is a question-answering datset, consisting of a paragraph as a context information, and question and its desirable answer, but the answer can be extracted from the paragraph. This task is to determine which part of the paragraph sentences contains the answers to the suggested questions. Actually, they removed the assumption that all the paragraphs have the answer span somewhere in the text in version 2. So a paragraph text may or may not possess the answer to the given question.
So what they did is converting the SQuAD QA task into sentence pair classification by forming a pair between each question and each sentence in the corresponding context, and filtering out pairs with low lexical overlap between the question and the context sentence.
Wrap Up
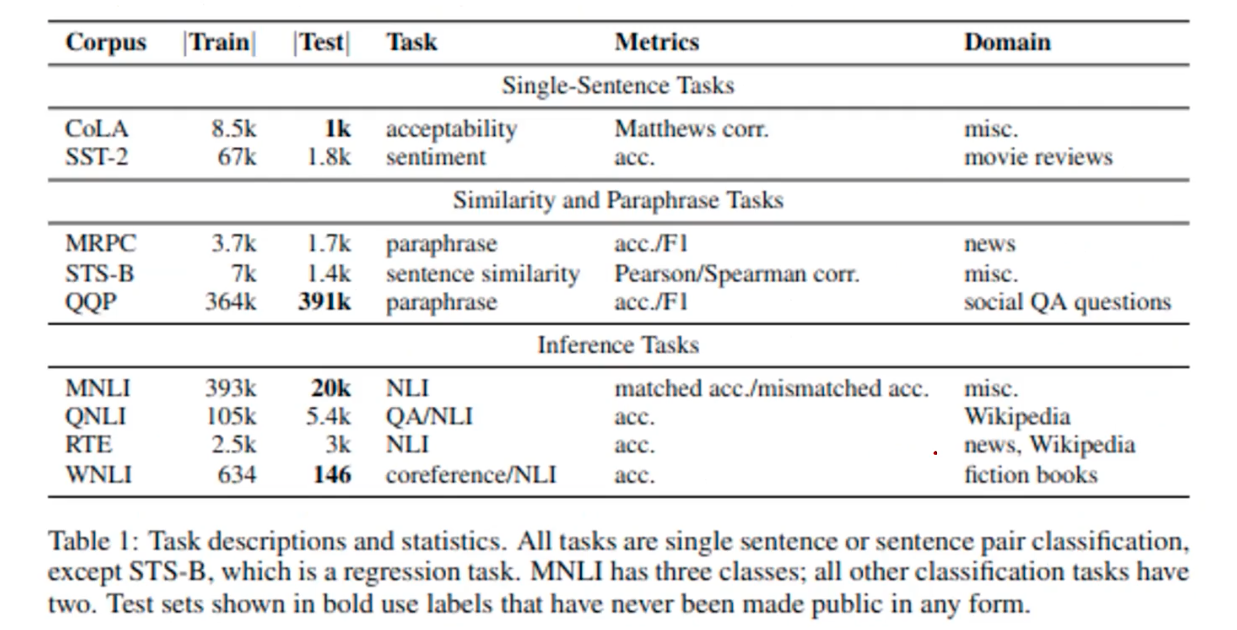
The overview of task description for GLUE benchmark. I skip other NLI datasets such as RTE and WNLI, but check out if you want.
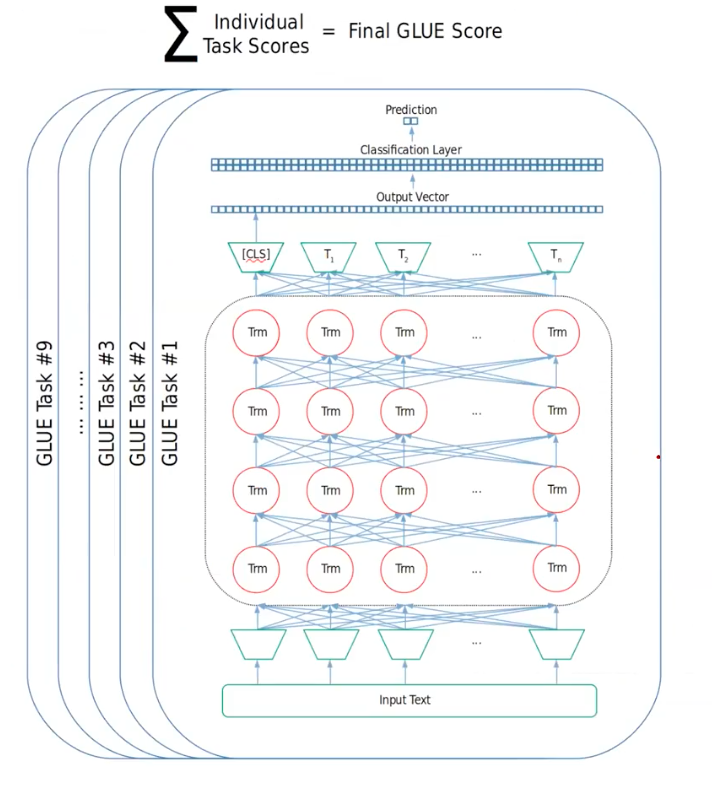
GLUE benchmark doen’t only provide the dataset, but also provide integrated framework to automatically load every 9 datasets and calculate the general GLUE scores based on each individual task score.
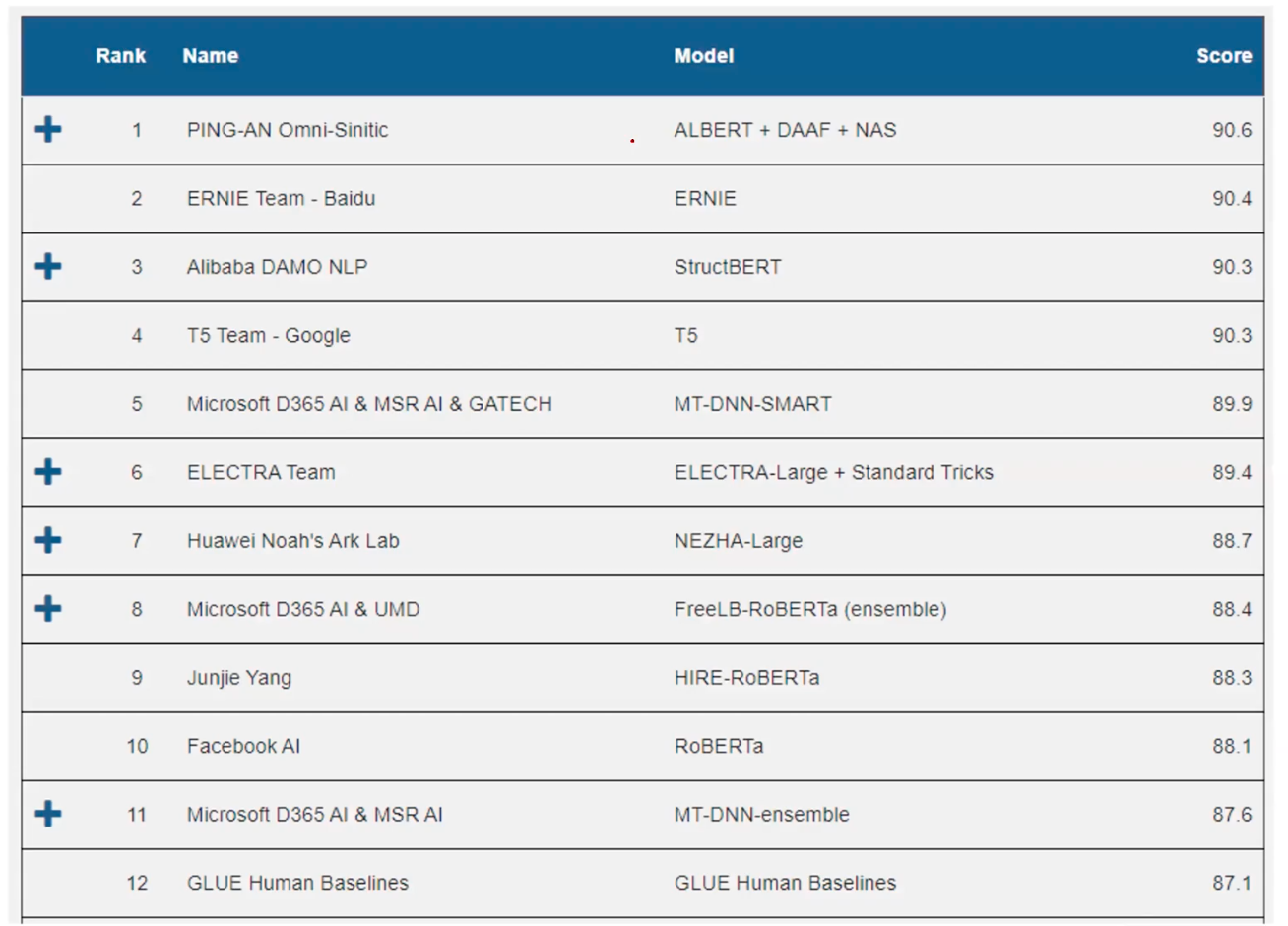
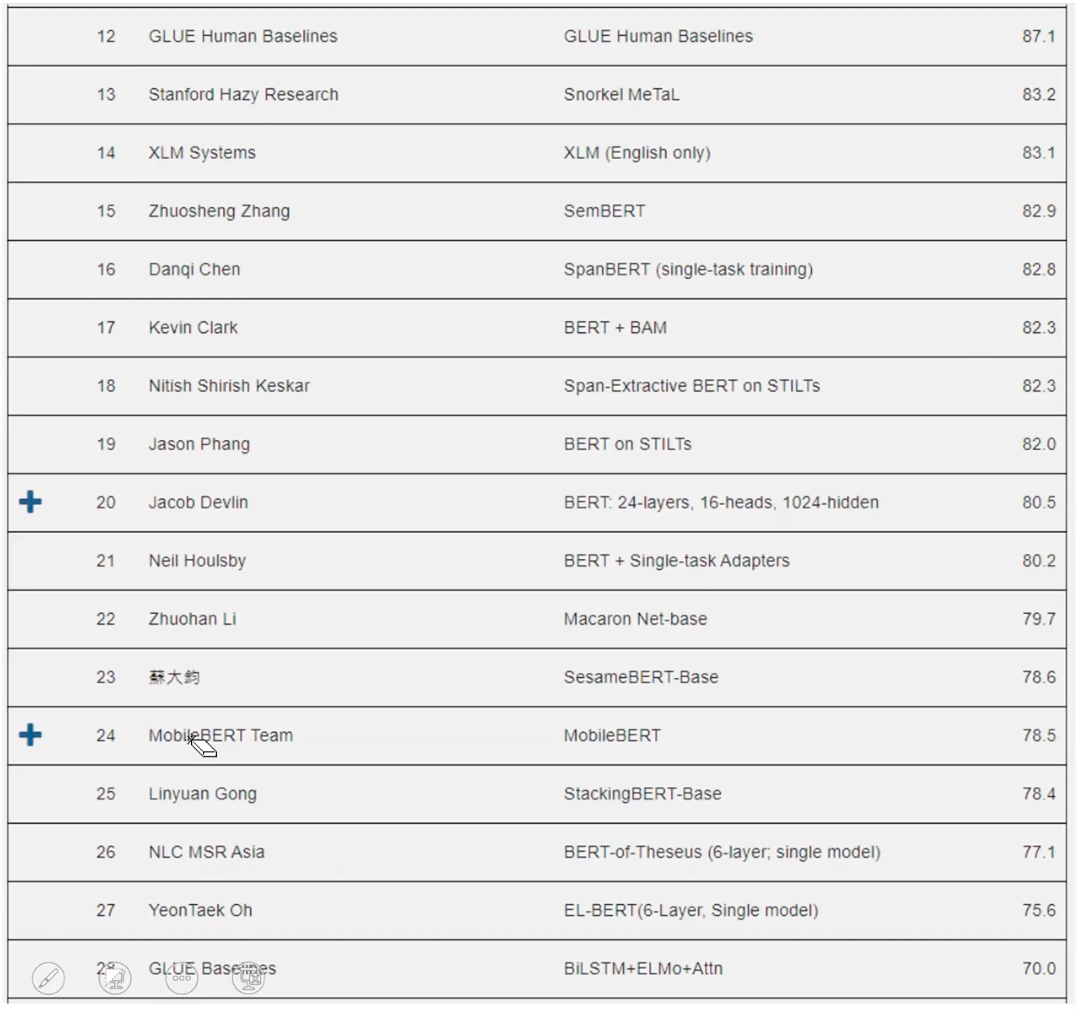
This is the leader board of GLUE benchmark, where SOTA models do better than humans!