Teaching Machines to Read

In this post, we’re trying to teach machines to read.
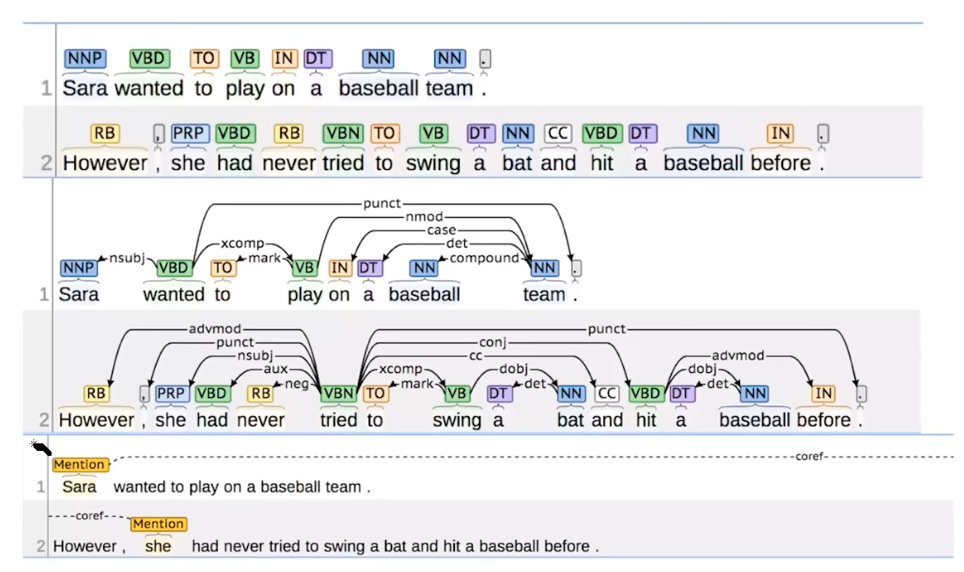
Should we be analysing the syntactic parse tree? Would such grammar rules extracted be useful for the machines to read?
Reading Comprehension as Question Answering

Early in the NLP, an evaluation approach to measure the reading comprehension of mahcines were introduced that let the model read some text and ask them to answer some questions. This still sounds reasonable.
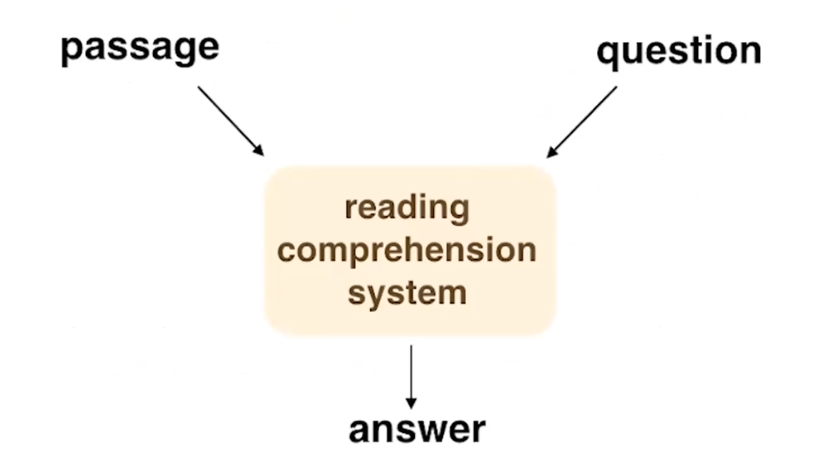
Reading comprehension can be casted as a question answering task, that demonstrate the understanding degree of NLP models. Given the input as text passage and the relavant questions, a reading comprehension system should correctly answer them.
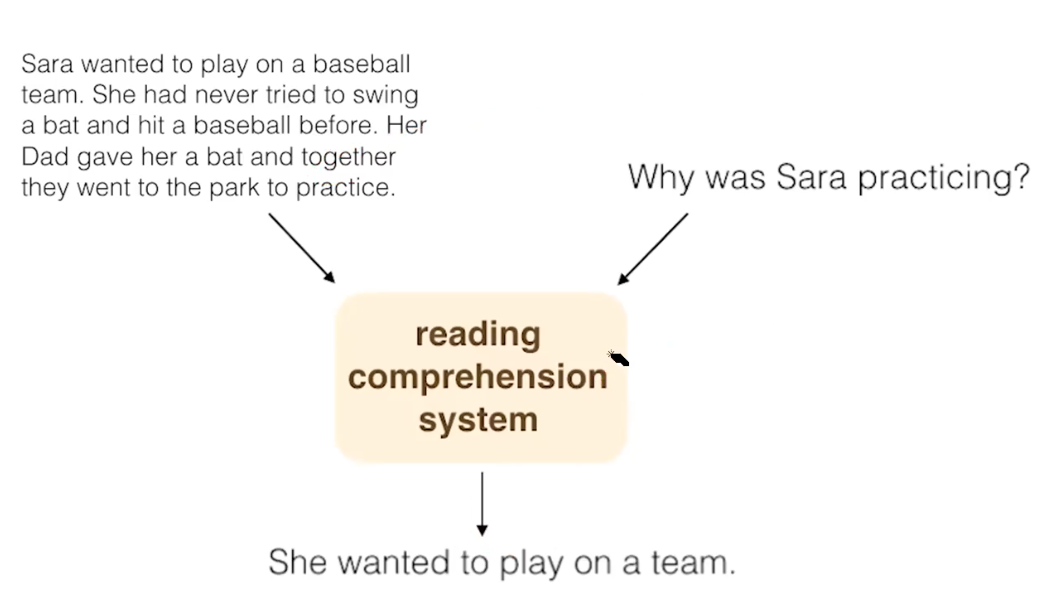
Reading Comprehension is a New Field
Before 2015, we hadn’t had any statistical NLP systems which is capable of reading a simple passage and answering questions.

Before 2015, there were few datasets and systems for reading comprehension. Such datasets had a limited amount of training samples.
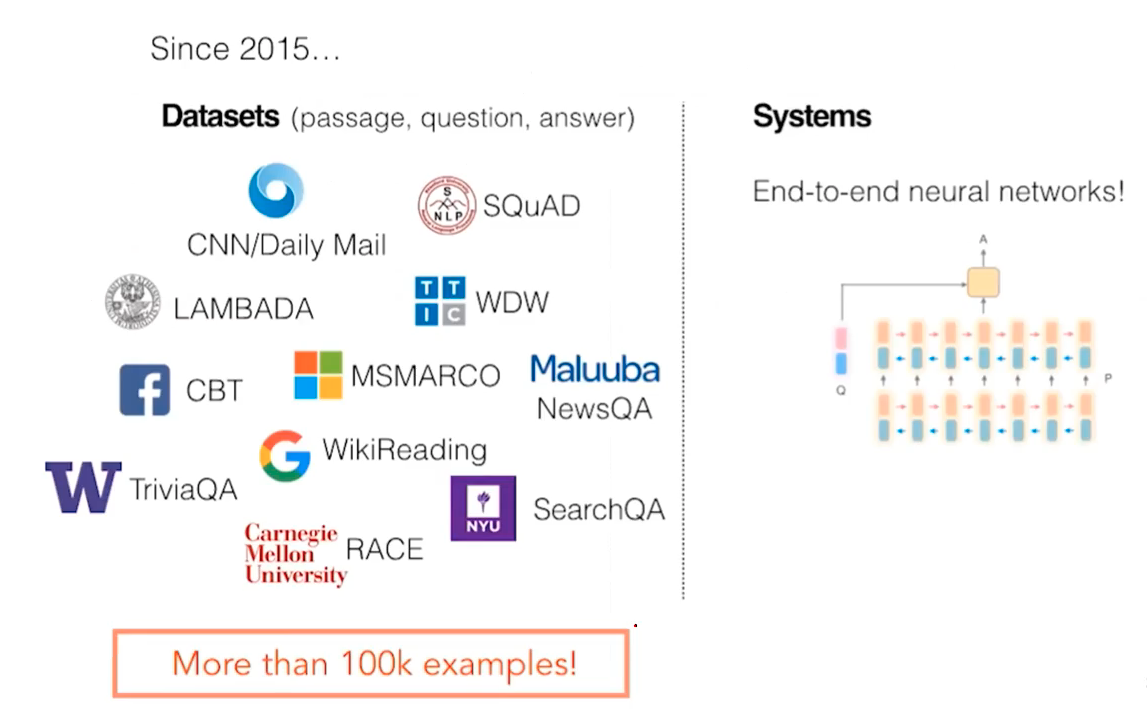
By 2015, there were sudden increase in both dataset and reading systems. All of such datasets are very diverse, capturing different aspects of human languages. These days, the regard 100K examples as large these days. 10K sized dataset is regarded as quite small, usually for small research. Regarding the systems, end-to-end deep learning neural networks were introduced!
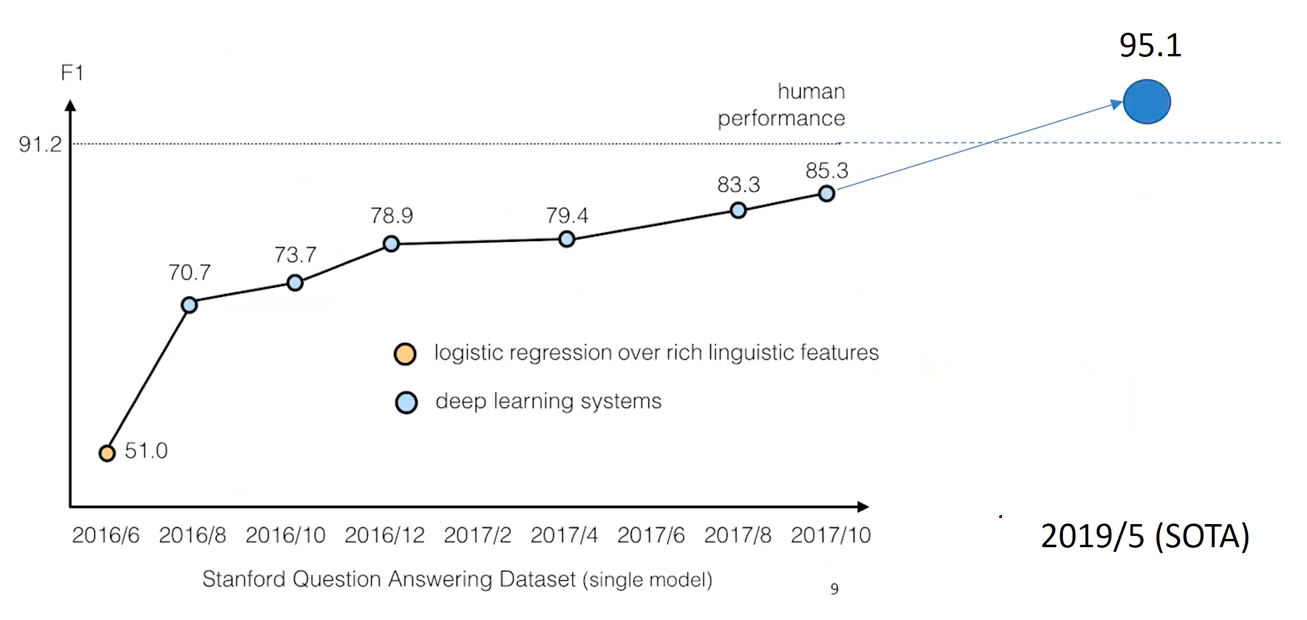
There was rapid progress since then. In SQuAD, which was released in 2016, within several months, machines exceeded humans! (due to the overfitting)
Outline

For the following section, we discuss datasets and model architecture for the machine reading comprehension task.
CNN/Daily Mail Datasets
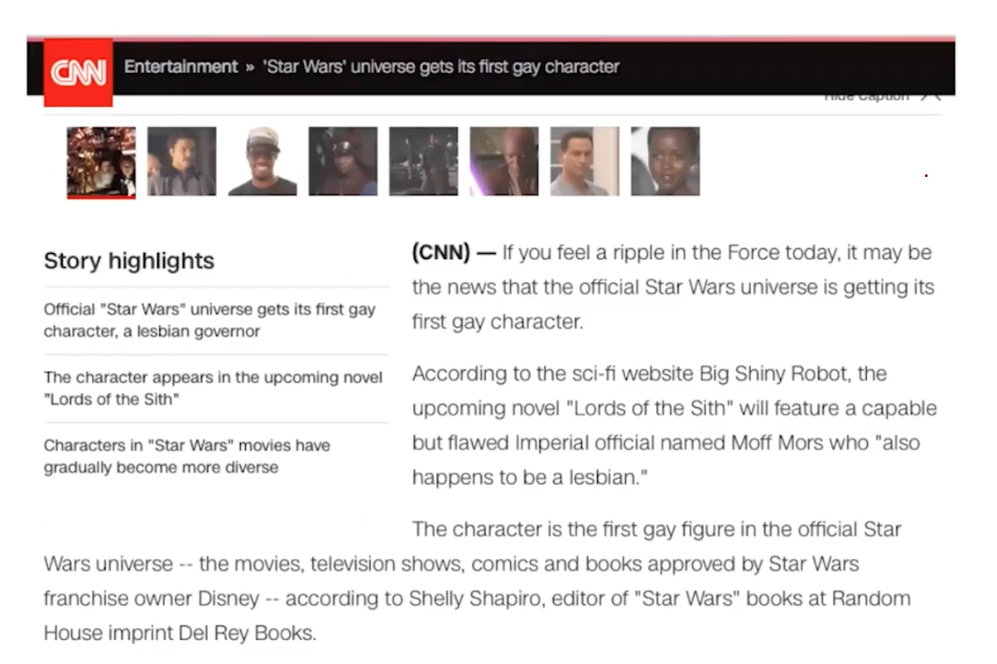
These datasets, provided by DeepMind, contains many document sets, where each sample passage has the average of 4 qeustions. story The highlights on for the article is given as a blank question for model to fill in the missing words. Precisely one entity or word is blanked out for each story highlight.

This dataset opened a new chapter in machine reading task beyond the machine translation task. They used an entity recognition model to identify well-known entities in the text. Then, they replaced such entities by this entity markers, which are special tokens. For the questions, they reused the highlights replacing some words by a placehoder marker. The goal of this task was to infer which entity refers to the marked placehodler. What a simple and free way to create a large-scale dataset; 380K for CNNs and 879 for Daily Mail.
Attentive Reader
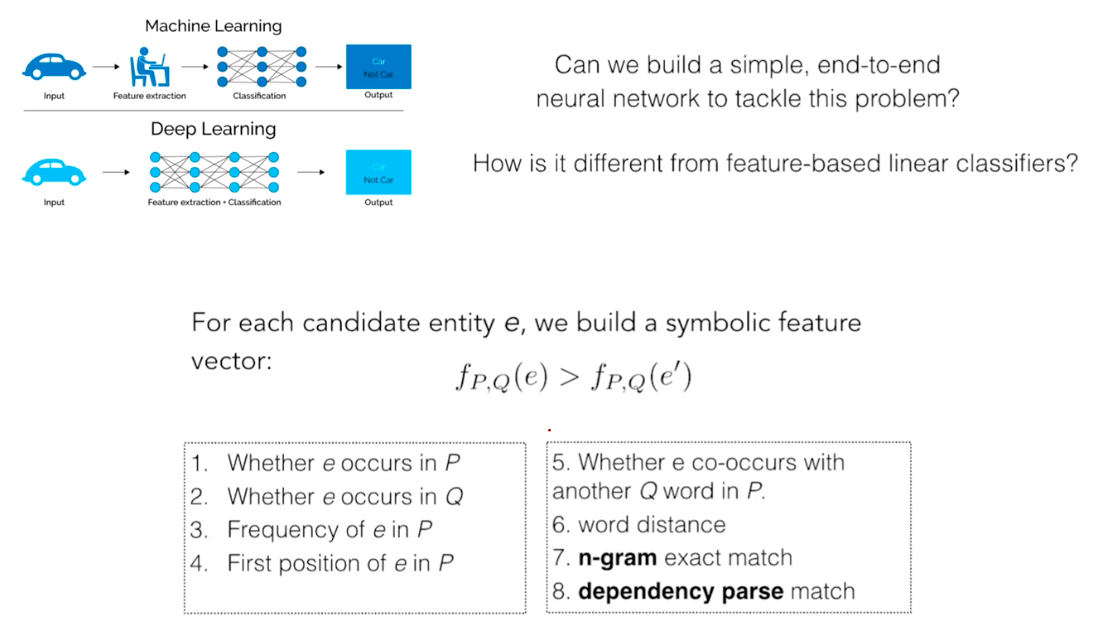
How to solve the task? They built a symbolic feature vector. By symbolic, we mean something that represent a feature in a catergorical way. In the figure above, linear classifiers are denoted as f, and an embedding as e. They prepared ab embedding e based on the 8 conditioned listed in the box below. Such heuristics are something like co-occurences, Jaccard similarity, etc. What they did was emprically engineer better feature representation.
But we could build a deep learning model that requires no further feature embedding. This is called this as attentive reader, where they encode question and passage to infer the answer based on their interaction in vector spaces. These are not symblic features, we call them numeric features.
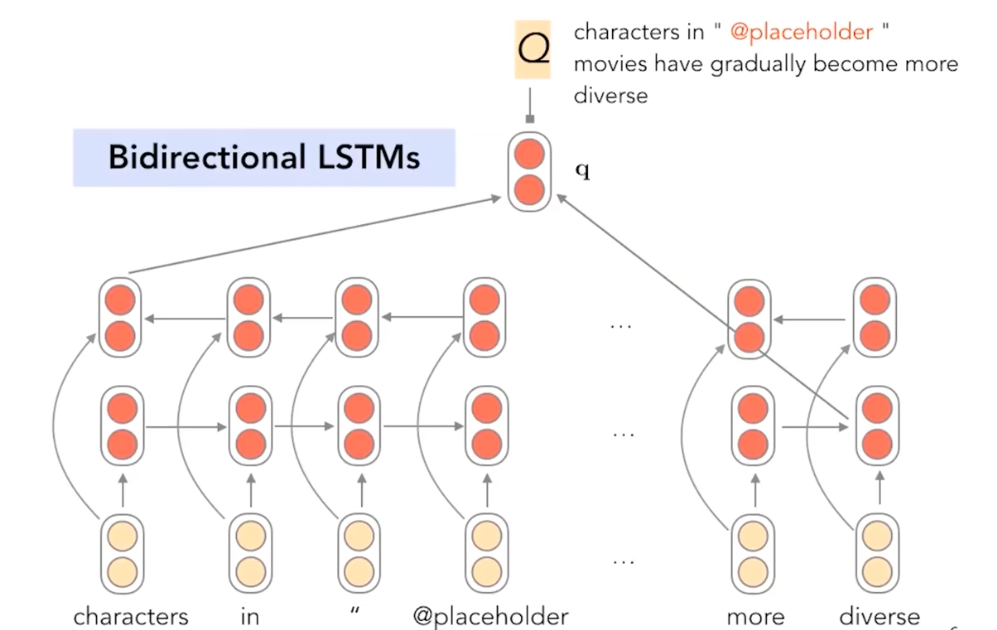
Given a question, the attentive reader used a sequential model (bidirecitonal LSTMs) to encode the question into a numeric (hidden) representation to solve the task.
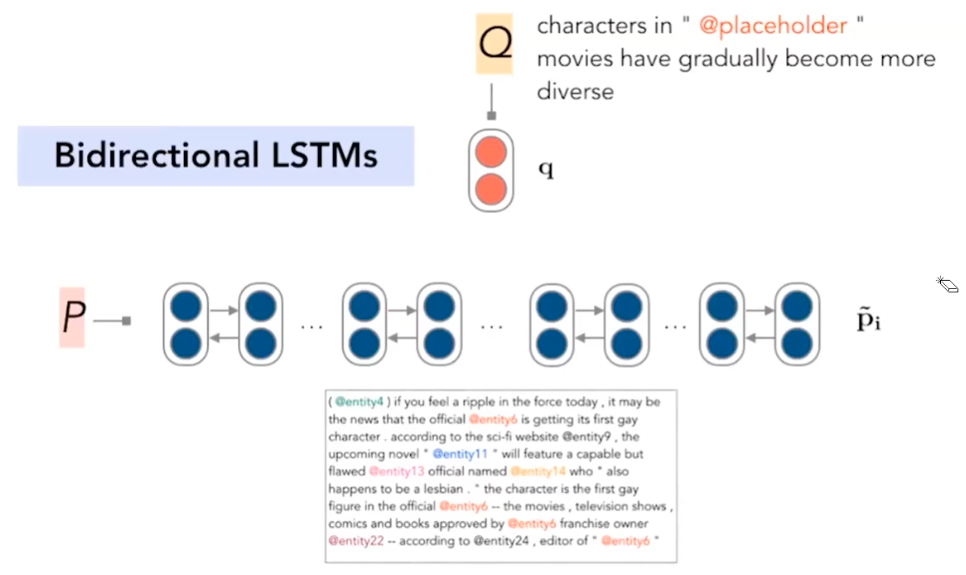
Then, attentive reader also used the LSTMs to encode words in the associated passage.
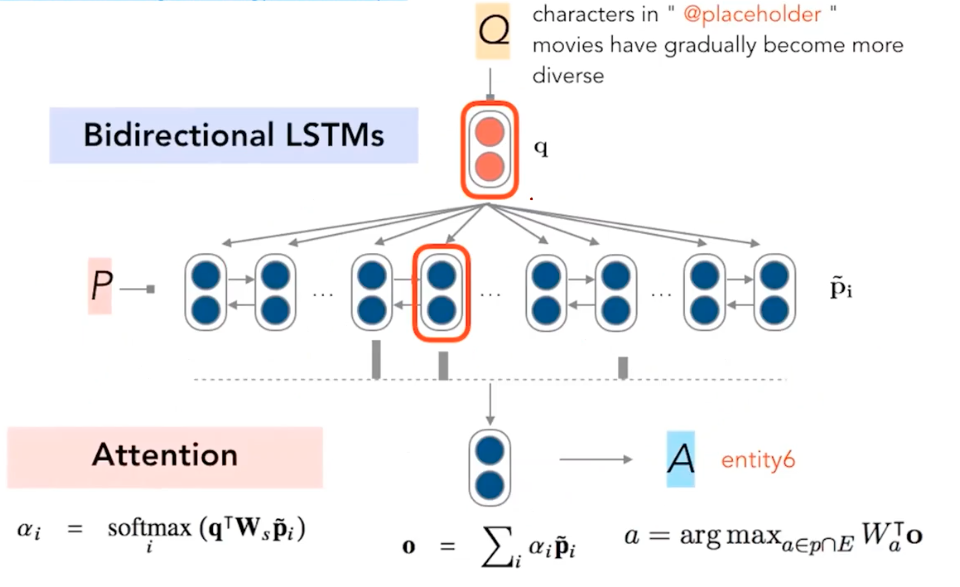
Finally, attentive reader used attention between a qeustion and all the bidirectional LSTM represetantions for words in a passage. Then the attention probability inferred points out which words are important and should be attended by the attentive reader. Then, aggregating the passage and the attention weights, the output vector is produced, projected via another linear layer to choose the a entity (among entity in the passage). Another attentive model (by DeepMind) were actually first proposed earlier to this version of attentive reader (by Stanford).
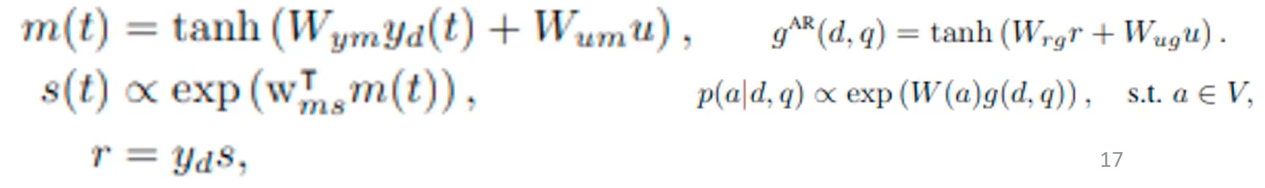
And it’s quite messy.
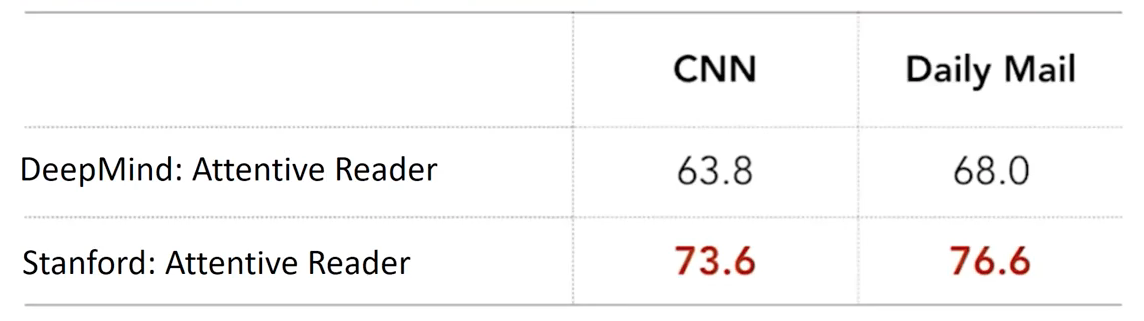
The Stanford attentive reader was not only simpler but its performance gain were massive.
What Do The Machines Understand?
What level of language understanding is needed? What have current models learned from machine reading comprehension task?

We are going to analyze the 6 cases where the machines learn to understand from the text.

In many cases, two sentences may have the exact matching text span, or share a sementic between two sentences. The first sentence that include a placeholder is the question sentence and the following sentences are of the context passage. If the system understand that two sentences save a similar meaning, then it should be able to predict the correct entity (entity 3 in the below example).

In cases of partial clue, there are no explicit evidence that the support the corresponding sentences. To complicate the problem more, the cases of multiple sentences refers when the system is required to answer an entity placed in a paragraph.
So what level of lanugage understanding is needed? People analysed the CNN/Daily Mail datasets and found that the paraphrasing and partial clue were the most frequently observed.

Data centric approach to improve the neural networks have been spotlighted, instead of model-centric progress. Historically, the progress to construct the benchmark dataset were the major efforts!
SQuAD, a QA Dataset

BiLSTMs with attention models were promising at learning semantic matching. But, does it work in a more real QA setup? There is a more realistic question-answering dataset called SQuAD. In this dataset, all answers can be extracted from the passage.

Here, passages were collected from real-world Wikipedia articles. The questions and answers were human crowdsourced. Here, the attentive reader model for SQuAD should find the starting point and the end point for the answer on the passage sentences. Therefore, models should predict two different probability distribution for the two points identification. Basically, for the model architecture, they are basically the same with the Stanford attentive reader. However, after the encoding, it predicts two probabilities. Unlike the previous task where we keep the sample independant entity candidates, in this task contains the answer in its passage. So, the attention mechanism to directly predict the probability of each word being the starting/ending point.
Case Study
Here we study a common failure case.

Given the question and passage, the correct answer is 2,400, and red 7,200 text span was predicted that is an incorrect answer. This suggest that the semantic/symoblic similarity between the question and answer sentences may mislead the model prediction, as it failed to distinguish the number of faculty from that of the student. The NNs are maybe doing some kind of cheating, taking “shortcuts” patterns that trivially overlap between the two sentences.

There is no clear explanation that San Diego is the second largest city. This kind of cases may require external knowledge.
DrQA, a Open-domain QA
SQuAD is still a restricted QA setup: questions that can be answered only by span selection, not generative approach. Also as annotators can see the paragraph when writing questions, high lexical overlap between question and paragraph is observed in SQuAD samples. Can we leverage reading comprehension systems for even broader open-domain question answering?
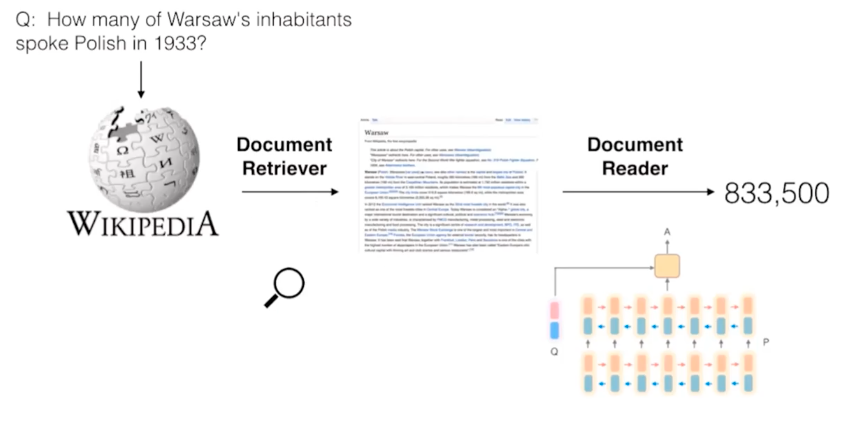
In DrQA, they use a information retrieval model (BM25), which is like a search engine, to retrieve the most relevant Wikipedia article, given a question. Then they used an attentive reader to find the answer in the article.
Specifically, they also proposed some heuristics for a better embedding representation.