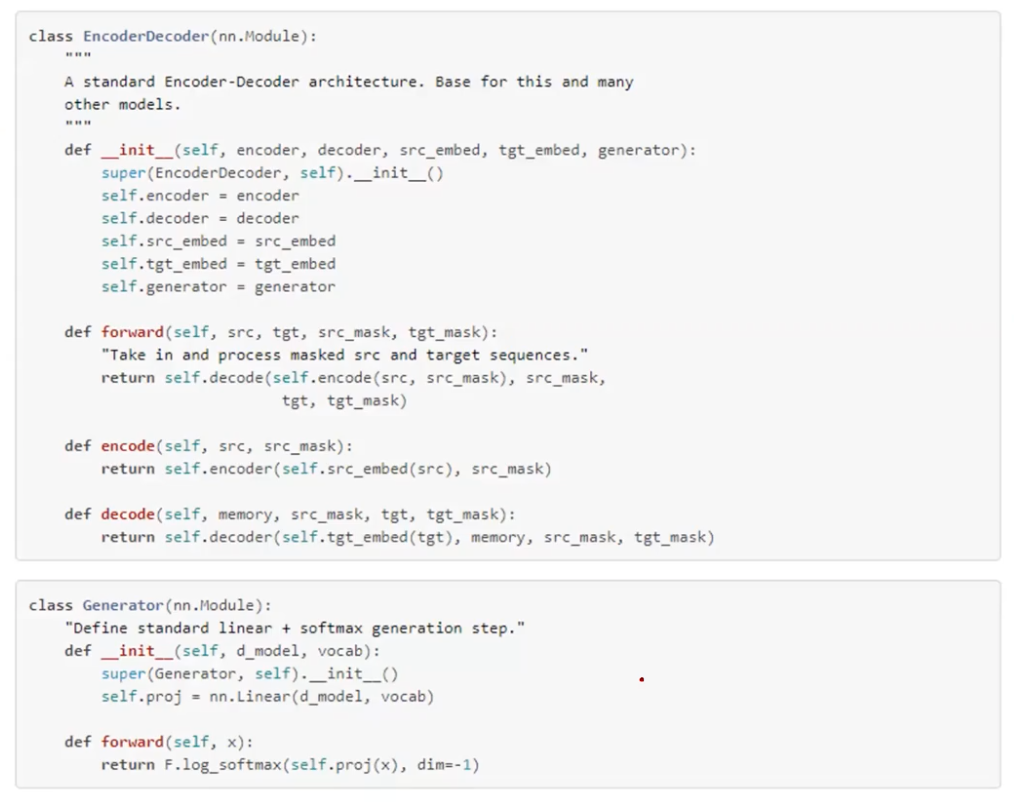
Teaching Machines to Read

So far, we talked about RNN -> LSTM -> Encoder-Decoder -> Seq2Seq (LSTMs) -> Seq2Seq with Attention. In this post, we extend the topic of using only attention. It claims that we don’t need recurrence in the processing the sequential data. They further redefine that language is a sequence of data. There have been quite a lot of work, where the language was not handled in not as a sequence, using CNNs on language input.
A High-level Look
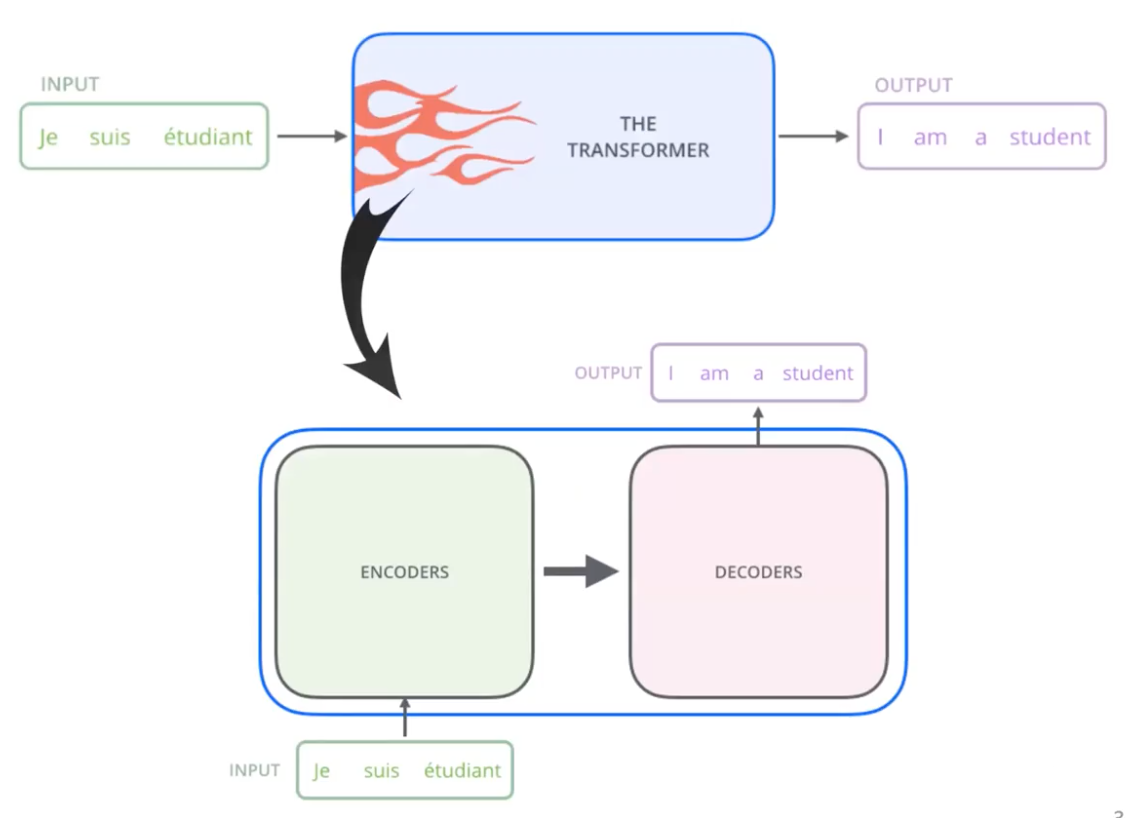
What they propose is the self-attention mechanism inside a encoder-decoder model. That is the key difference between the Seq2Seq model and the Transformers. On the upper figure, we are seeing the transformer layers as a blackbox model that takes input of sequence and produce output of sequence.
Take a little closer look, the transformer consists of the encoding part, decoding part, and their connection in between. Both layers are a stack of some amount of encoding/decoding layers, each having its own parameters (no sharing among them). Usually, they use both 6 layers, but it depends. However, we set the same number of layers on both sides.
It’s quite huge model, so you need both enough traning data and a good computer. Inside each encoding layer, two sub-layer exist, one of which is the “self-attention” layer and the other being a general feed-forward neural network (FFNs). Input words are the input of the self-attention layers, which encode individual word embedding as a weighted sum of other words. When given this kind of sentences as input, we tokenize (splitting into tokens while converting the symbolic word index in the numeric token index). Given a target word, we see other words serve as a context to the target word. Our purpose of using self-attention is using representation of a target word as a weighted sum of other neighboring word representation. Lastly, we aggregate the self-attention representation of different multiple words via a FFN.
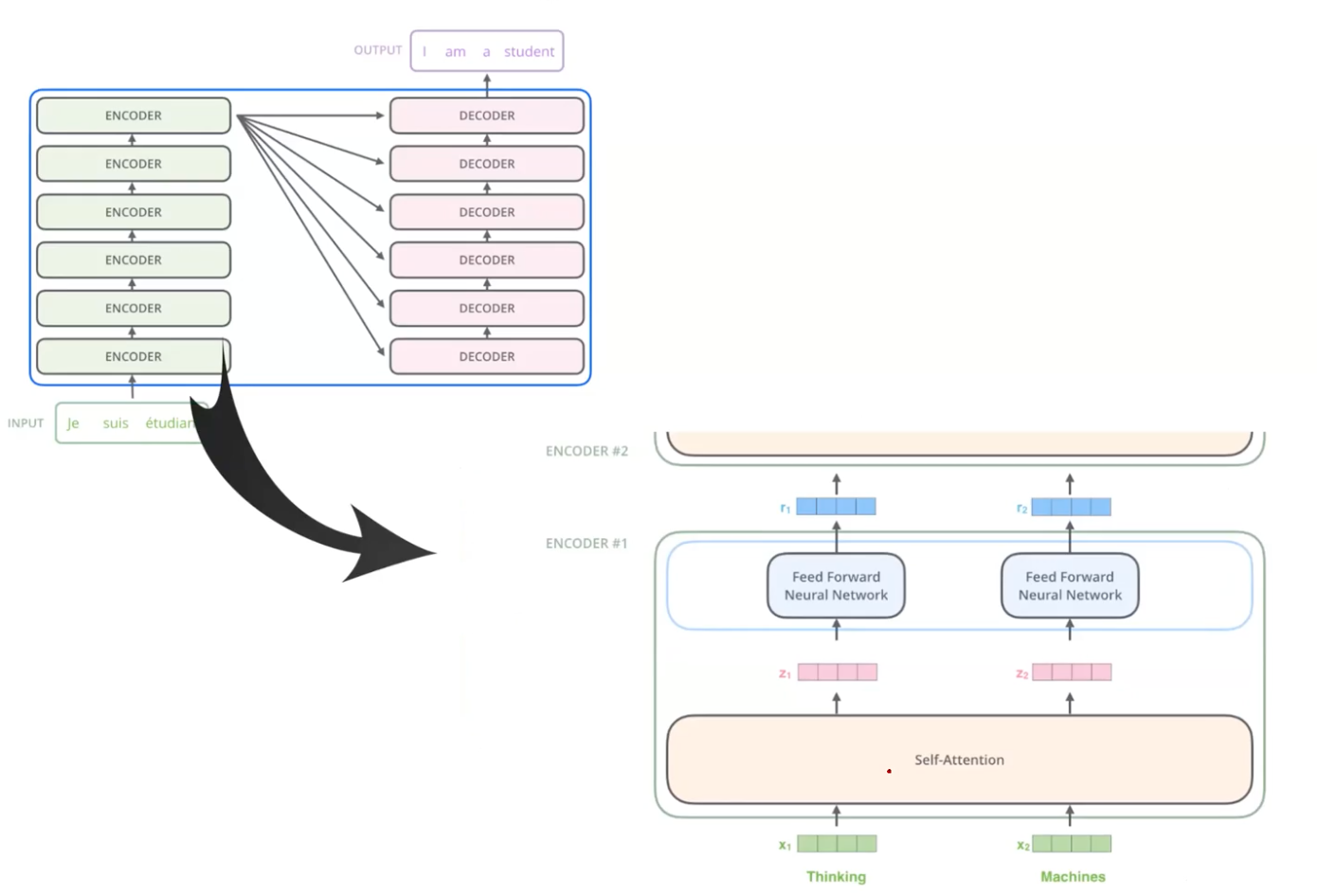
Take a closer look. Each and every word goes through the FFN (unique and shared across each word position. The greens are the input tokens, and the pink hidden representation is passed into the one single FFN independantly. Generally, transformer-like neural networks don’t use the word embedding layers.